|
CSharp: Separar páginas pdf en un pdf por cada página con PDFsharp y Visual C# C Sharp

Explicamos en este tutorial cómo generar un fichero PDF por cada página de un fichero PDF origen. Mostramos cómo desarrollar una aplicación de tratamiento de ficheros PDF de forma nativa (sin necesidad de tener instalado software de terceros), como ejemplo explicamos paso a paso cómo dividir un fichero PDF en ficheros PDF destino, uno por cada página. Para ello usaremos la DLL gratuita PDFsharp y el lenguaje de programación Microsoft Visual C# C Sharp .Net 2010. Publicamos una aplicación completa de ejemplo con el código fuente en VB.Net: AjpdSoft Separar Páginas PDF.
Videotutorial: AjpdSoft Separar Páginas PDFA continuación mostramos un videotutorial donde explicamos el funcionamiento y uso de la aplicación gratuita y open source AjpdSoft Separar Páginas PDF:
Descarga del componente gratuito PDFsharpPara desarrollar una aplicación de tratamiento de ficheros PDF (portable document format ó formato de documento portátil) usaremos la librería gratuita PDFsharp, por lo tanto necesitaremos descargar el fichero de esta librería dll. Accederemos a la URL:
Descargaremos la versión más reciente de PDFsharp, en nuestro caso: PDFsharp 1.32. Descargaremos el fichero PDFsharp-MigraDocFoundation-Assemblies-1_32.zip, lo descomprimiremos. Este fichero contiene las siguientes librerías:
Para realizar nuestro proyecto de separar o dividir un fichero PDF en tantos ficheros PDF como páginas contenga (un fichero PDF por cada página) usaremos la librería "PdfSharp.dll" ubicada en .../PDFsharp-MigraDocFoundation-Assemblies-1_32/GDI+. Copiaremos este fichero a la carpeta que queramos (por ejemplo la raíz de nuestros proyectos). Más adelante deberemos seleccionarlo desde nuestro proyecto C# .Net. PDFsharp está desarrollada en Microsoft Visual C# y, además, es posible descargar el código fuente completo pues es un proyecto Open Source.
Instalación de Microsoft Visual Studio .NetPara desarrollar la aplicación que nos permita trabajar con ficheros PDF usaremos el lenguaje de programación Microsoft Visual C# ó Visual C Sharp. En este tutorial dividiremos un fichero PDF origen en tantos ficheros PDF destino como páginas tenga, generaremos un fichero PDF con cada página del fichero PDF origen. Usaremos la suite de desarrollo Microsoft Visual Studio .Net. En el siguiente tutorial explicamos cómo instalar esta suite de desarrollo:
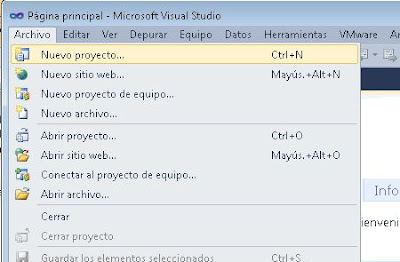
Separar páginas PDF con C# C Sharp y PDFsharpA continuación explicaremos cómo crear un proyecto o solución en Visual C# .Net para dividir un fichero PDF en tantos ficheros como páginas tenga, un fichero PDF destino por cada página del PDF origen. Para ello abriremos Visual Studio .Net, pulsaremos en el menú "Archivo" - "Nuevo proyecto":
Seleccionaremos en la parte izquierda "Otros lenguales " - "Visual C# ", en la parte derecha seleccionaremos "Aplicación de Windows Forms" e introduciremos el nombre del proyecto, por ejemplo "AjpdSoftSepararPaginasPDF":
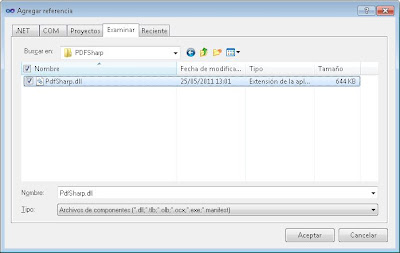
Agregaremos la referencia a PDFsharp, para ello pulsaremos en el menú "Proyecto" - "Agregar referencia":
Pulsaremos en la pestaña "Examinar" y seleccionaremos el fichero "PdfSharp.dll" descargado anteriormente:
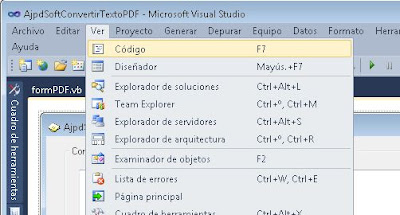
Añadiremos los "imports" al proyecto, para ello pulsaremos en el menú "Ver" - "Código":
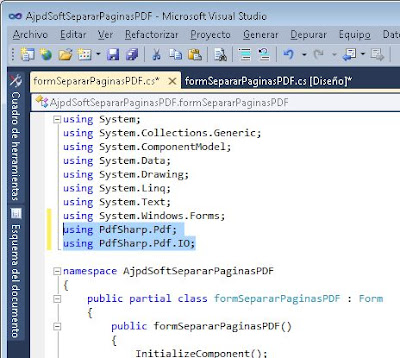
Al principio agregaremos el siguiente código:
Añadiremos los siguientes componentes al formulario principal de nuestra aplicación para dividir ficheros PDF:
A continuación mostramos el código fuente C# C Sharp .Net de cada botón y cada evento:
private void btSelPDFOrigen_Click(object sender, EventArgs e)
private void txtFicheroPDFOrigen_TextChanged(object sender, EventArgs e)
{
string rutaFicheroPDFOrigenDividir = txtFicheroPDFOrigen.Text;
if (File.Exists(rutaFicheroPDFOrigenDividir))
{
try
{
PdfDocument ficheroPDFOrigenDividir =
PdfReader.Open(rutaFicheroPDFOrigenDividir, PdfDocumentOpenMode.InformationOnly);
txtNombre.Text =
Path.GetFileNameWithoutExtension(rutaFicheroPDFOrigenDividir);
txtTitulo.Text = ficheroPDFOrigenDividir.Info.Title;
txtAutor.Text = ficheroPDFOrigenDividir.Info.Author;
txtAsunto.Text = ficheroPDFOrigenDividir.Info.Subject;
txtPalabrasClave.Text = ficheroPDFOrigenDividir.Info.Keywords;
lInfoPDF.Text = "Nº de páginas: " + ficheroPDFOrigenDividir.PageCount +
", se generarán " + ficheroPDFOrigenDividir.PageCount +
" ficheros PDF, uno por cada página del fichero PDF origen";
}
catch (Exception errorM)
{
MessageBox.Show("Error al leer fichero PDF." +
System.Environment.NewLine + System.Environment.NewLine +
errorM.Message, "Error al abrir PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
private void bSelCarpetaDestinoPDF_Click(object sender, EventArgs e)
{
dlCarpeta.RootFolder = System.Environment.SpecialFolder.Desktop;
dlCarpeta.ShowNewFolderButton = true;
dlCarpeta.Description = "Selecciona la carpeta de destino de los ficheros " +
"PDF resultantes de extraer cada página del PDF " +
"origen en un fichero PDF destino";
if (dlCarpeta.ShowDialog() == DialogResult.OK)
{
txtCarpetaDestinoPDF.Text = dlCarpeta.SelectedPath;
}
}
private void btSepararPaginasPDF_Click(object sender, EventArgs e)
{
try
{
string rutaFicheroPDFOrigenDividir = txtFicheroPDFOrigen.Text;
if (!File.Exists(rutaFicheroPDFOrigenDividir))
{
MessageBox.Show("El fichero origen del que se extraerán las páginas " +
"en ficheros PDF divididos no existe.", "Fichero origen PDF no existe",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtFicheroPDFOrigen.Focus();
}
else
{
if (!Directory.Exists(txtCarpetaDestinoPDF.Text))
{
MessageBox.Show("La carpeta de destino donde se crearán los " +
"ficheros PDF de las páginas extraídas no existe.",
"Carpeta destino para PDF no existe",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtCarpetaDestinoPDF.Focus();
}
else
{
PdfDocument ficheroPDFOrigenDividir =
PdfReader.Open(rutaFicheroPDFOrigenDividir, PdfDocumentOpenMode.Import);
string nombreFicheroDestinoPaginasPDF =
Path.GetFileNameWithoutExtension(txtNombre.Text);
lInfoProgreso.Text = "Extrayendo páginas de fichero PDF";
lInfoProgreso.Refresh();
bp.Minimum = 0;
bp.Maximum = ficheroPDFOrigenDividir.PageCount;
bp.Value = 0;
for (int paginaPDFActual = 0;
paginaPDFActual < ficheroPDFOrigenDividir.PageCount;
paginaPDFActual++)
{
lInfoProgreso.Text = "Dividiendo página " +
Convert.ToString(paginaPDFActual + 1);
lInfoProgreso.Refresh();
// Crear el documento PDF destino de la página extraida
PdfDocument ficheroPDFPaginaDestino = new PdfDocument();
ficheroPDFPaginaDestino.Info.Subject = txtAsunto.Text;
ficheroPDFPaginaDestino.Info.Title = txtTitulo.Text;
ficheroPDFPaginaDestino.Info.Author = txtAutor.Text;
ficheroPDFPaginaDestino.Info.Keywords = txtPalabrasClave.Text;
ficheroPDFPaginaDestino.Info.Creator = Application.ProductName;
ficheroPDFPaginaDestino.Info.ModificationDate = DateTime.Now;
/*
ficheroPDFPaginaDestino.Info.Title =
String.Format("Página {0} de {1}", paginaPDFActual + 1,
ficheroPDFOrigenDividir.PageCount);
*/
// Añadir la página y guardar el fichero PDF creado
ficheroPDFPaginaDestino.AddPage(ficheroPDFOrigenDividir.Pages[paginaPDFActual]);
string nombreFicheroPDFDestino = Path.Combine(txtCarpetaDestinoPDF.Text,
nombreFicheroDestinoPaginasPDF + " - Página " +
Convert.ToString(paginaPDFActual + 1)) + ".pdf";
ficheroPDFPaginaDestino.Save(nombreFicheroPDFDestino);
lsFicherosPDFDivididos.Items.Add(nombreFicheroPDFDestino);
bp.Value = paginaPDFActual + 1;
}
lInfoProgreso.Text = "Fichero dividido en páginas correctamente: se han generado " +
Convert.ToString(ficheroPDFOrigenDividir.PageCount) + " ficheros PDF";
lInfoProgreso.Refresh();
}
}
}
catch (Exception errorM)
{
MessageBox.Show("Error al extraer páginas de fichero PDF." +
System.Environment.NewLine + System.Environment.NewLine +
errorM.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
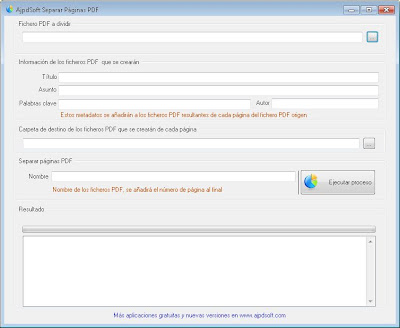
AjpdSoft Separar Páginas PDFAjpdSoft Separar Páginas PDF permite dividir un fichero PDF en tantos ficheros PDF como páginas tenga. Es decir, AjpdSoft Separar Páginas PDF creará un fichero PDF con una página correspondiente a cada página del fichero PDF origen. Por ejemplo, queremos dividir un fichero PDF con 10 páginas, AjpdSoft Separar Páginas PDF generará 10 ficheros PDF, cada uno con cada página del PDF origen. AjpdSoft Separar Páginas PDF no necesita usar impresoras PDF ni Acrobat Professional ni ningún software de terceros, únicamente usa la librería gratuita PDFsharp.dll. El manejo de la aplicación es muy sencillo, en primer lugar seleccionaremos el fichero PDF origen, el fichero PDF que dividiremos o partiremos. Para ello pulsaremos en el botón "..." de "Fichero PDF a dividir":
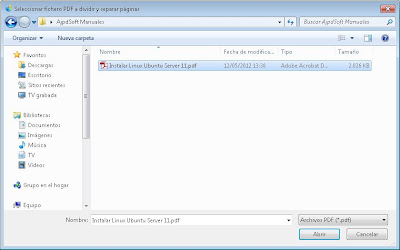
Seleccionaremos el fichero PDF a dividir y pulsaremos "Abrir":
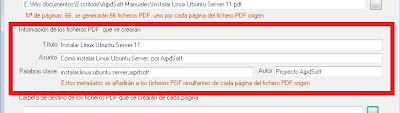
AjpdSoft Separar Páginas PDF obtendrá el número de páginas del fichero PDF así como los metadatos título, asunto, palabras clave y autor. Introduciremos los metadatos que qeuramos, serán los que se guarden en cada fichero PDF generado:
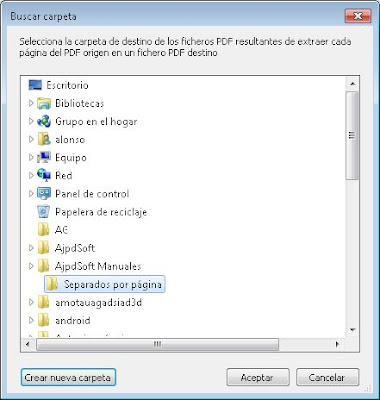
Seleccionaremos ahora la carpeta de destino donde se crearán todos los ficheros PDF resultantes de la división del PDF origen, es importante crear una carpeta pues si son muchos ficheros se crearán en donde elijamos. Para seleccionar una carpeta pulsaremos el botón "..." en "Carpeta de destino de los ficheros PDF que se crearán de cada página":
Seleccionaremos la carpeta de destino:
Indicaremos el nombre para los ficheros PDF resultantes de la división del PDF origen, se creará un fichero PDF con este nombre por cada página, seguido del número de página. Una vez introducido el nombre del fichero PDF destino pulsareoms en "Ejecutar proceso":
AjpdSoft Separar Páginas PDF iniciará el proceso de división del fichero PDF, mostrará una barra de progreso indicando el estado de la operación. En la parte inferior mostrará todos los ficheros PDF generados. Cuando el proceso concluya nos mostrará el texto "Fichero dividido en páginas correctamente, se han generado xxx". Desde la propia aplicación AjpdSoft Separar Páginas PDF podremos abrir los ficheros PDF generados haciendo doble clic sobre cualquiera de ellos:
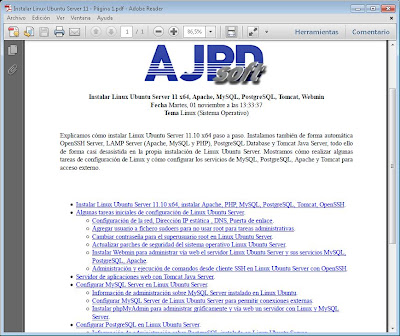
Se iniciará la aplicación que tengamos establecida por defecto para abrir ficheros PDF, en nuestro caso Acrobat Reader, con el fichero PDF seleccionado. Dicho fichero contendrá una página correspondiente al fichero PDF origen:
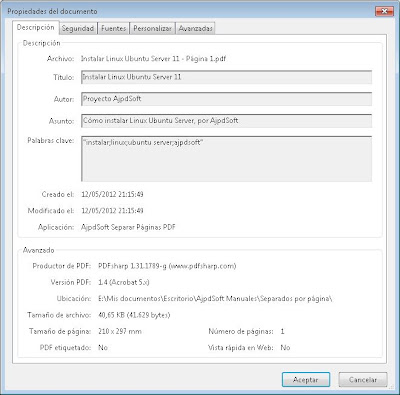
Consultando las propiedades del fichero PDF generado podremos ver los metadatos introducidos anteriormente (título, autor, asunto, palabras clave):
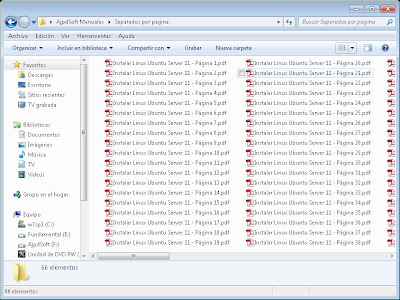
Y se habrá creado un fichero PDF con una página por cada página del fichero PDF origen:
Código fuente completo de AjpdSoft Separar Páginas PDFA continuación mostramos el enlace para descargar gratuitamente el código fuente completo de la aplicación AjpdSoft Separar Páginas PDF desarrollada con C# C Sharp .Net 2010 (Microsoft Studio .Net 2010): El listado completo del código fuente de la aplicación AjpdSoft Separar Páginas PDF: using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using PdfSharp.Pdf;
using PdfSharp.Pdf.IO;
namespace AjpdSoftSepararPaginasPDF
{
public partial class formSepararPaginasPDF : Form
{
public formSepararPaginasPDF()
{
InitializeComponent();
}
private void linkAjpdSoft_LinkClicked(object sender,
LinkLabelLinkClickedEventArgs e)
{
System.Diagnostics.Process.Start("http://www.ajpdsoft.com");
}
private void btSelPDFOrigen_Click(object sender, EventArgs e)
{
dlAbrir.CheckFileExists = true;
dlAbrir.CheckPathExists = true;
dlAbrir.Multiselect = false;
dlAbrir.DefaultExt = "pdf";
dlAbrir.FileName = "";
dlAbrir.Filter = "Archivos PDF (*.pdf)|*.pdf|Todos los archivos (*.*)|*.*";
dlAbrir.Title = "Seleccionar fichero PDF a dividir y separar páginas";
if (dlAbrir.ShowDialog() == DialogResult.OK)
{
txtFicheroPDFOrigen.Text = dlAbrir.FileName;
}
}
private void bSelCarpetaDestinoPDF_Click(object sender, EventArgs e)
{
dlCarpeta.RootFolder = System.Environment.SpecialFolder.Desktop;
dlCarpeta.ShowNewFolderButton = true;
dlCarpeta.Description = "Selecciona la carpeta de destino de los ficheros " +
"PDF resultantes de extraer cada página del PDF " +
"origen en un fichero PDF destino";
if (dlCarpeta.ShowDialog() == DialogResult.OK)
{
txtCarpetaDestinoPDF.Text = dlCarpeta.SelectedPath;
}
}
private void btSepararPaginasPDF_Click(object sender, EventArgs e)
{
try
{
string rutaFicheroPDFOrigenDividir = txtFicheroPDFOrigen.Text;
if (!File.Exists(rutaFicheroPDFOrigenDividir))
{
MessageBox.Show("El fichero origen del que se extraerán las páginas " +
"en ficheros PDF divididos no existe.", "Fichero origen PDF no existe",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtFicheroPDFOrigen.Focus();
}
else
{
if (!Directory.Exists(txtCarpetaDestinoPDF.Text))
{
MessageBox.Show("La carpeta de destino donde se crearán los " +
"ficheros PDF de las páginas extraídas no existe.",
"Carpeta destino para PDF no existe",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtCarpetaDestinoPDF.Focus();
}
else
{
PdfDocument ficheroPDFOrigenDividir =
PdfReader.Open(rutaFicheroPDFOrigenDividir, PdfDocumentOpenMode.Import);
string nombreFicheroDestinoPaginasPDF =
Path.GetFileNameWithoutExtension(txtNombre.Text);
lInfoProgreso.Text = "Extrayendo páginas de fichero PDF";
lInfoProgreso.Refresh();
bp.Minimum = 0;
bp.Maximum = ficheroPDFOrigenDividir.PageCount;
bp.Value = 0;
for (int paginaPDFActual = 0;
paginaPDFActual < ficheroPDFOrigenDividir.PageCount;
paginaPDFActual++)
{
lInfoProgreso.Text = "Dividiendo página " +
Convert.ToString(paginaPDFActual + 1);
lInfoProgreso.Refresh();
// Crear el documento PDF destino de la página extraida
PdfDocument ficheroPDFPaginaDestino = new PdfDocument();
ficheroPDFPaginaDestino.Info.Subject = txtAsunto.Text;
ficheroPDFPaginaDestino.Info.Title = txtTitulo.Text;
ficheroPDFPaginaDestino.Info.Author = txtAutor.Text;
ficheroPDFPaginaDestino.Info.Keywords = txtPalabrasClave.Text;
ficheroPDFPaginaDestino.Info.Creator = Application.ProductName;
ficheroPDFPaginaDestino.Info.ModificationDate = DateTime.Now;
/*
ficheroPDFPaginaDestino.Info.Title =
String.Format("Página {0} de {1}", paginaPDFActual + 1,
ficheroPDFOrigenDividir.PageCount);
*/
// Añadir la página y guardar el fichero PDF creado
ficheroPDFPaginaDestino.AddPage(ficheroPDFOrigenDividir.Pages[paginaPDFActual]);
string nombreFicheroPDFDestino = Path.Combine(txtCarpetaDestinoPDF.Text,
nombreFicheroDestinoPaginasPDF + " - Página " +
Convert.ToString(paginaPDFActual + 1)) + ".pdf";
ficheroPDFPaginaDestino.Save(nombreFicheroPDFDestino);
lsFicherosPDFDivididos.Items.Add(nombreFicheroPDFDestino);
bp.Value = paginaPDFActual + 1;
}
lInfoProgreso.Text = "Fichero dividido en páginas correctamente: se han generado " +
Convert.ToString(ficheroPDFOrigenDividir.PageCount) + " ficheros PDF";
lInfoProgreso.Refresh();
}
}
}
catch (Exception errorM)
{
MessageBox.Show("Error al extraer páginas de fichero PDF." +
System.Environment.NewLine + System.Environment.NewLine +
errorM.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
private void txtFicheroPDFOrigen_TextChanged(object sender, EventArgs e)
{
string rutaFicheroPDFOrigenDividir = txtFicheroPDFOrigen.Text;
if (File.Exists(rutaFicheroPDFOrigenDividir))
{
try
{
PdfDocument ficheroPDFOrigenDividir =
PdfReader.Open(rutaFicheroPDFOrigenDividir, PdfDocumentOpenMode.InformationOnly);
txtNombre.Text =
Path.GetFileNameWithoutExtension(rutaFicheroPDFOrigenDividir);
txtTitulo.Text = ficheroPDFOrigenDividir.Info.Title;
txtAutor.Text = ficheroPDFOrigenDividir.Info.Author;
txtAsunto.Text = ficheroPDFOrigenDividir.Info.Subject;
txtPalabrasClave.Text = ficheroPDFOrigenDividir.Info.Keywords;
lInfoPDF.Text = "Nº de páginas: " + ficheroPDFOrigenDividir.PageCount +
", se generarán " + ficheroPDFOrigenDividir.PageCount +
" ficheros PDF, uno por cada página del fichero PDF origen";
}
catch (Exception errorM)
{
MessageBox.Show("Error al leer fichero PDF." +
System.Environment.NewLine + System.Environment.NewLine +
errorM.Message, "Error al abrir PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
private void lsFicherosPDFDivididos_DoubleClick(object sender, EventArgs e)
{
if (lsFicherosPDFDivididos.SelectedIndex >= 0)
{
string ficheroPDF = lsFicherosPDFDivididos.SelectedItem.ToString();
if (File.Exists(ficheroPDF))
{
System.Diagnostics.Process.Start(ficheroPDF);
}
else
{
MessageBox.Show("El fichero PDF seleccionado no existe " +
"o se ha cambiado de ubicación.",
"Fichero PDF no existe",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
}
}
}
}
Artículos relacionados
CréditosArtículo realizado íntegramente por Alonsojpd miembro fundador del Proyecto AjpdSoft. Anuncios
Enviado el Domingo, 13 mayo a las 00:37:46 por ajpdsoft
|
|